MST Deployment Models: Zero Compute vs. Pilot Light
Overview
In my previous post, I covered what Multicloud Snapshot Technology (MST) is, the object stores it supports, and where it fits in your DR strategy. Now I want to dig into the decision that shapes most of your MST architecture: which deployment model to use.
Nutanix offers two distinct approaches, Zero Compute and Pilot Light, and they trade off cost against recovery speed in ways that matter a lot depending on the workloads you are protecting. Getting this decision right can mean the difference between a recovery that takes minutes and one that takes hours, with very different cost profiles along the way.
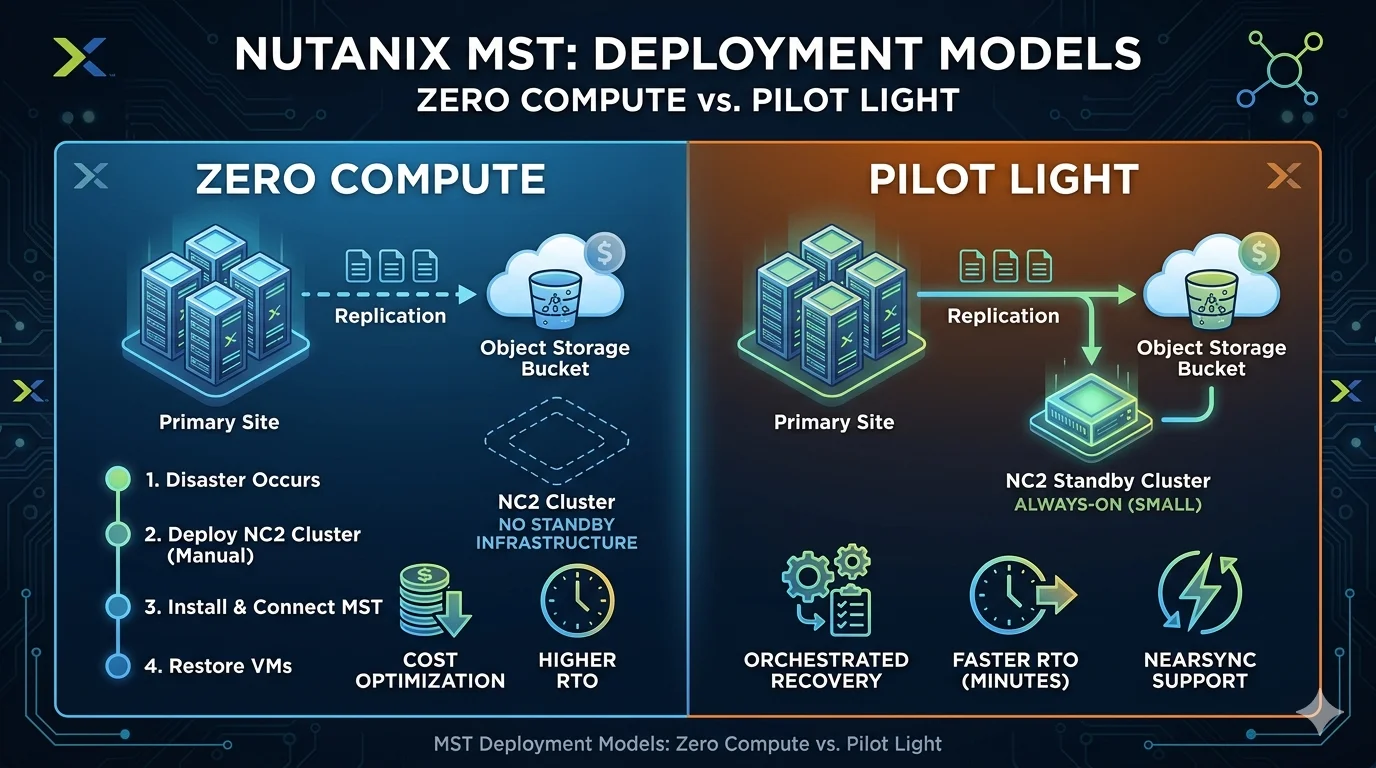
Zero Compute
Zero Compute is the most cost-effective MST deployment model. In this configuration, there is no standby infrastructure running in the cloud. Snapshots replicate from your on-premises cluster to the object store on a schedule (asynchronous replication with a minimum 1-hour RPO), and those are the only cloud resources you consume during normal operations.
When a disaster occurs, you manually deploy an NC2 cluster in the cloud, install MST on it pointing to the same snapshot bucket, and restore your VMs from the recovery points. The workflow is: deploy the cluster, deploy MST from the Prism Central Marketplace, connect it to the existing bucket, and then clone VMs from the available recovery points.
The trade-off is time. Spinning up an NC2 cluster and restoring workloads is not instantaneous, and the failback process requires manual coordination since Zero Compute does not automatically maintain a reverse replication relationship. After recovery, you need to create a non-MST asynchronous protection policy from the NC2 cluster back to on-premises and execute a planned failover to migrate workloads home. Once everything is back, you re-deploy MST on the primary cluster to resume snapshot replication.
Zero Compute is a strong fit for workloads where cost optimization is the priority and you can tolerate a longer recovery window. Think development environments, archival systems, or secondary workloads where hours of RTO are acceptable.
Pilot Light
Pilot Light takes a different approach. In this model, a small NC2 cluster is always running in the cloud with MST deployed and connected to the same snapshot bucket. The on-premises and cloud MST instances communicate through dedicated ports (30990/TCP for the control service and 30900/TCP for the data service), maintaining an active relationship between sites.
The key advantage is that Pilot Light supports recovery plans in Prism Central. That means you can define orchestrated failover sequences, run test failovers to validate your runbooks, and execute unplanned failovers with a defined process. For critical workloads replicated directly to the Pilot Light NC2 cluster (rather than just to the bucket), you can even use NearSync replication with minute-level RPO.
There is one important detail around recovery plans and MST: when recovering VMs to the NC2 cluster, you may need to expand the cluster capacity to accommodate the workload. Prism Central will warn you if the recovery set exceeds available resources, and you can add nodes through the NC2 console before proceeding.
Pilot Light also supports the Instant Restore capability that shipped in Prism Central 7.5.1, which I will cover in detail in my next post. The short version: VMs can power on before full data hydration completes, with data fetched on demand in the background. The combination of Pilot Light and Instant Restore gives you an MST-based DR solution with recovery times measured in minutes rather than hours.
The trade-off is cost. You are paying for a small always-on cluster in the cloud, even during normal operations. But for mission-critical workloads where RTO matters, that ongoing cost is typically easy to justify against the alternative of extended downtime.
Choosing Between Them
The decision often comes down to finding the right balance between budget, resilience, and recoverability. Most organizations I work with are trying to stretch their DR investment as far as it will go, which usually means using both models: Zero Compute for the bulk of their workloads where cost matters most, and Pilot Light for the subset of mission-critical applications that need faster recovery.
MST supports composite protection rules that make this practical. You can define different replication targets within the same protection policy, sending critical workloads to both the bucket and the Pilot Light NC2 cluster while routing everything else to the bucket only. This lets you mix deployment models without managing entirely separate DR strategies.
When building composite rules, explicitly add a recovery location that defines the reverse replication direction. This is especially important for bucket-based replication since object storage is unidirectional. If you skip this step and the NC2 cluster experiences an issue after failover, your recovered VMs have no replication protecting them. Nutanix strongly recommends defining the reverse schedule to ensure continued coverage.
How This Compares to Traditional DR
If you are evaluating MST, you are probably also weighing it against two other common approaches: maintaining your own secondary DR site or using a Disaster Recovery as a Service (DRaaS) provider. It is worth understanding where the MST models sit relative to both.
A self-managed DR site gives you the most control. You own the hardware, you control the replication, and you define every aspect of the recovery process. The trade-off is that you are paying for and maintaining a full secondary environment, whether you use it or not. That means capital expenditure on hardware, ongoing costs for power, cooling, and facilities, plus the operational overhead of keeping the DR site patched, tested, and in sync with production. For organizations with the budget and staff to support it, a dedicated DR site can deliver aggressive RTOs and RPOs. But for many teams, it is more infrastructure than they can justify for workloads that may never fail over.
DRaaS providers take that operational burden off your plate. You get a managed recovery environment without owning the underlying infrastructure, and most providers handle replication, testing, and orchestration as part of the service. The trade-off is cost and flexibility. DRaaS subscriptions can get expensive at scale, and you are typically locked into the provider's tooling, supported platforms, and recovery workflows. If your environment does not fit neatly into their model, you may end up paying for customizations or accepting compromises on recovery targets.
MST with Zero Compute lands somewhere between the two from a cost perspective. You are not maintaining a full DR site, and you are not paying a DRaaS provider's monthly subscription. Your ongoing cost is object storage for snapshots, and you only spin up compute when you actually need it. The trade-off is that recovery is slower and more manual than either alternative, which makes it best suited for workloads where you can accept a longer RTO.
MST with Pilot Light is closer to what a DRaaS provider delivers, but you retain control of the Nutanix stack. You have an always-on recovery target with orchestrated failover, test capabilities, and the option for Instant Restore. The cost is lower than a full DR site since you are running a minimal cluster rather than mirroring your entire production footprint, and you avoid the platform lock-in that comes with most DRaaS offerings.
In practice, the comparison is not always one-or-the-other. Some organizations use MST alongside an existing DR strategy, layering Zero Compute protection on workloads that were previously unprotected because the cost of replicating them to a secondary site or adding them to a DRaaS contract was not justifiable. That incremental coverage is one of the more practical benefits of MST's cost model.
What Comes Next
With the deployment models covered, the last piece of this MST series is the feature that prompted me to revisit the technology in the first place: Instant Restore. In my next post, I will walk through how it decouples VM recovery from data hydration and why it changes the RTO conversation for MST-protected workloads.
Working through your MST deployment model decision or running a hybrid Zero Compute and Pilot Light setup? I'd love to hear how you're approaching it. Connect with me on LinkedIn or reach out at mike@mikedent.io.